この題材は非常に多くの人が実施し、記事にもなっていますが手元にCurrent_Pending_Sector(代替処理保留中のセクタ数)が発生したHDDがあったので不良セクタの代替え処理を試し、S.M.A.R.Tのエラーを解消してみようと思います。
注意
今回ここで使用するコマンドはやっていることの内容を理解せずに実行するとデータを消失する可能性があります。やっていることの内容を理解し、自己責任で操作するようにして下さい。
ここで使用するHDDは何もデータが入っていないものを使用しています。データが入っているHDDの場合は更に多くの手順を実施する必要があります。
1. 環境
・ハードディスク
種類:Western Digital Red[2TB]
接続:SATA(マザーボードに直結)
・OS
種類:Linux(CentOS8)
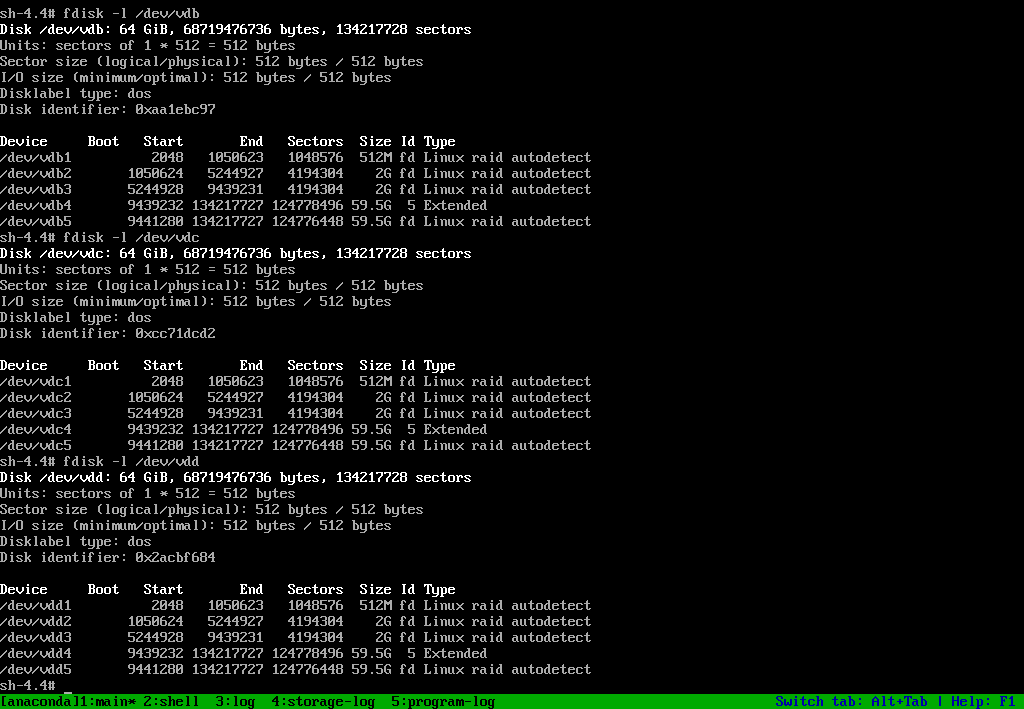
2. HDDの状況
smartctlの結果はこんな状態です。4年くらい前にサーバーで使用していたもので短命なHDDだったなと思っていたのですが、最近WD Redを購入してサーバーに組み込んだら1週間も経たないうち(160時間)にCurrent_Pending_Sectorが発生しました。WD Redは自分とは相性が悪いのかもしれません・・・
# smartctl -a /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD20EFRX-68EUZN0
Serial Number: WD-WCC4M6CL2PLE
LU WWN Device Id: 5 0014ee 2638bc189
Firmware Version: 82.00A82
User Capacity: 2,000,398,934,016 bytes [2.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 1.5 Gb/s)
Local Time is: Wed May 13 07:15:54 2020 JST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 121) The previous self-test completed having
the read element of the test failed.
Total time to complete Offline
data collection: (25980) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 263) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x703d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 3640
3 Spin_Up_Time 0x0027 207 173 021 Pre-fail Always - 2641
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 33
5 Reallocated_Sector_Ct 0x0033 182 182 140 Pre-fail Always - 545
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 091 091 000 Old_age Always - 7196
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 31
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 19
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 265
194 Temperature_Celsius 0x0022 120 108 000 Old_age Always - 27
196 Reallocated_Event_Count 0x0032 149 149 000 Old_age Always - 51
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 3
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 108
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed: read failure 90% 7196 23027200
# 2 Extended offline Completed: read failure 90% 7196 14746760
# 3 Short offline Completed without error 00% 7195 -
# 4 Extended offline Completed: read failure 90% 7186 14746760
# 5 Extended offline Completed: read failure 90% 7186 14766264
# 6 Short offline Completed without error 00% 7182 -
# 7 Short offline Completed: read failure 90% 7182 16281440
# 8 Short offline Completed: read failure 90% 7182 14750152
# 9 Extended offline Completed: read failure 90% 7136 14740632
#10 Extended offline Completed: read failure 90% 7136 16207904
#11 Extended offline Completed: read failure 90% 7136 16207904
#12 Extended offline Completed: read failure 90% 7136 14750152
#13 Short offline Completed without error 00% 7136 -
#14 Short offline Completed: read failure 90% 7135 14740537
#15 Short offline Completed: read failure 90% 7135 14740536
#16 Conveyance offline Completed: read failure 90% 7135 14740537
#17 Extended offline Completed: read failure 90% 7135 14741008
#18 Short offline Completed: read failure 90% 7120 14741008
#19 Short offline Completed: read failure 90% 7120 14741008
#20 Extended offline Completed: read failure 90% 7118 14741008
#21 Extended offline Completed: read failure 90% 7118 14741008
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
ベンダー固有の属性情報を見てみるとCurrent_Pending_Sector(代替処理保留中のセクタ数)が3件存在しており、すでにReallocated_Sector_Ct(代替処理済のセクタ数)は545件存在しています。
3. 不良セクタの代替処理とは
 HDDは右の写真のようにプラッタと呼ばれる銀色の円盤に磁気情報を記録することにより情報を保存しています。この銀色の円盤には磁性体と呼ばれるものが塗られており、これが磁気を帯びることで情報を保存するのですが、経年劣化や傷などにより磁性体が磁気を帯びにくくなったり剥がれたりすると、その場所への情報の読み書きができなくなります。この場所のことを不良セクタと呼びます。
HDDは右の写真のようにプラッタと呼ばれる銀色の円盤に磁気情報を記録することにより情報を保存しています。この銀色の円盤には磁性体と呼ばれるものが塗られており、これが磁気を帯びることで情報を保存するのですが、経年劣化や傷などにより磁性体が磁気を帯びにくくなったり剥がれたりすると、その場所への情報の読み書きができなくなります。この場所のことを不良セクタと呼びます。
不良セクタへは読み込みも書き込みも行えなくなるわけですが、HDDには予めある程度予備の領域が用意されており、ファームウェアが不良セクタへの書き込みを検知すると以後不良セクタではなく予備の領域へアクセスするようにします。これが不良セクタの代替処理です。
そしてセクタサイズで区切った場合に代替処理を行っていない不良セクタが何箇所あるかを表しているのがCurrent_Pending_Sectorの値であり、この不良セクタへの書き込みが行われ代替処理が行われたセクタの数がReallocated_Sector_Ctの値となります。
4. 不良セクタの代替処理を実際に試して見る
3に記載したとおり、不良セクタに対して書き込み処理を行うことで不良セクタが代替されます。不良セクタの位置を知らないと書き込みが行えないので、まず最初に不良セクタの位置を確認します。
4-1. 不良セクタの位置を知る
不良セクタの位置を知るにはS.M.A.R.Tのセルフテストの機能を使用します。不良セクタがある場合は2で示したsmart情報の83行目LBA_of_first_error列にセクタ番号が表示されます。
手順
- S.M.A.R.Tのshortテストを行う。
- テスト結果LBA_of_first_errorを確認する。
- 2で結果が得られなかった場合はS.M.A.R.Tのlongテストを行う。
- テスト結果LBA_of_first_errorを確認する。
longテストの場合、長い時間待つように(例では263分)言われますが、不良セクタを見つけるとその時点でテスト終了となるため場合にもよりますが、比較的短時間で結果が得られます。
以下、上記手順の例です。
# smartctl -t short /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Wed May 13 07:20:31 2020
Use smartctl -X to abort test.
# smartctl -l selftest /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 7196 -
# 2 Extended offline Completed: read failure 90% 7196 23027200
# 3 Extended offline Completed: read failure 90% 7196 14746760
・・・
# smartctl -t long /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Extended self-test routine immediately in off-line mode".
Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 263 minutes for test to complete.
Test will complete after Wed May 13 11:44:12 2020
Use smartctl -X to abort test.
# smartctl -l selftest /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed: read failure 90% 7196 23033488
# 2 Short offline Completed without error 00% 7196 -
# 3 Extended offline Completed: read failure 90% 7196 23027200
・・・
以上から不良セクタのひとつは23033488 だと分かります。
4-2. 不良セクタへ書き込みを行う
ここではddコマンドを使用する方法と、hdparmコマンドを使用する方法を紹介します。
4-2-1. 最初に読み込みを行ってみる
ddコマンドを使用して不良セクタから値を読み取って見るとこのようにエラーとなります。bsには2のsmartctlの結果12行目に書かれているセクタサイズを指定します。
# dd if=/dev/sde of=/dev/null bs=512 count=1 skip=23033488
dd: '/dev/sde' の読み込みエラー: 入力/出力エラーです
0+0 レコード入力
0+0 レコード出力
0 bytes copied, 7.02786 s, 0.0 kB/s
4-2-2. hdparmコマンドで書き込みしてみる
# hdparm --write-sector 23033488 --yes-i-know-what-i-am-doing /dev/sde
/dev/sde:
re-writing sector 23033488: succeeded
# dd if=/dev/sde of=/dev/null bs=512 count=1 skip=23033488
1+0 レコード入力
1+0 レコード出力
512 bytes copied, 3.08049 s, 0.2 kB/s
書き込み後はこのように読み取りができるようになります。
4-2-3. ddコマンドで書き込みしてみる
# dd if=/dev/zero of=/dev/sde bs=512 count=1 seek=23027200
dd: '/dev/sde' の書き込みエラー: 入力/出力エラーです
1+0 レコード入力
0+0 レコード出力
0 bytes copied, 3.51744 s, 0.0 kB/s
# dd if=/dev/zero of=/dev/sde bs=512 count=1 seek=23027200
1+0 レコード入力
1+0 レコード出力
512 bytes copied, 0.000406069 s, 1.3 MB/s
# dd if=/dev/sde of=/dev/null bs=512 count=1 skip=23027200
1+0 レコード入力
1+0 レコード出力
512 bytes copied, 2.34536 s, 0.2 kB/s
ddコマンドで書き込む際は(私の環境では?)2回実施が必要でした。
4-3. ベンダー固有の属性情報を確認する
# smartctl -A /dev/sde
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-4.18.0-147.8.1.el8_1.x86_64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 3672
3 Spin_Up_Time 0x0027 207 173 021 Pre-fail Always - 2641
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 33
5 Reallocated_Sector_Ct 0x0033 182 182 140 Pre-fail Always - 547
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 091 091 000 Old_age Always - 7197
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 31
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 19
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 266
194 Temperature_Celsius 0x0022 119 108 000 Old_age Always - 28
196 Reallocated_Event_Count 0x0032 148 148 000 Old_age Always - 52
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 1
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 107
今回2つの不良セクタについて対応したので、Current_Pending_Sectorが3→1件に、Reallocated_Sector_Ctが545→547件と変化しました。
4-4. すべてのエラーを解消するには
4-1と4-2の手順を繰り返し実施します。
5. まとめ
不良セクタの代替処理について確認することができました、機会があればデータが入っているHDDに対してもやってみたいですね。